안녕하세요! 행복한 잡러입니다!

오늘은 ChatGPT에서 새로 나온 신작 모델인 o3-mini와 o3-mini-high에 대한
정보 소개와 전작 o1과의 성능 비교를 알아보겠습니다.

최근 중국의 DeepSeek에서 공개한 LLM 모델이 큰 파장을 불러왔습니다.
모델 크기는 o1에 비해 훨씬 작고, 학습에 이용한 GPU 칩들도 여러 저성능 칩들을 마개조한
칩들을 사용하였다고 알려졌는데 그 성능은 o1과 비슷하거나 능가하였기 때문입니다.
중국이기 때문에 많은 사람들이 그 진위 여부에 대해 의심할 수 있겠지만
논문도 공개하였고 모델 코드까지 모두가 확인할 수 있도록 공개하면서
이에 대해 증명하였습니다.

그러자 이것 때문인지는 모르겠으나 ChatGPT에서도 갑자기 새로운 모델을 공개하였습니다.
올해 공개한다고 알려져있던 o3 라인 모델인데요,
다만 메인 o3 모델은 아니고, o3-mini와 o3-mini-high 모델 입니다.
이 두 모델은 특히 수학, 코딩, 과학 등 STEM 분야에서 뛰어난 성능을 발휘하면서,
전작인 o1(및 o1‑mini)에 비해 응답 속도, 비용 효율성, 안전성 측면에서 혁신적인 개선을 이루었습니다.
이제부터 각 모델의 주요 특징과 차별점을 자세히 살펴보겠습니다.
o3‑mini: 비용 효율적 추론의 새 지평
- 주요 목표: 기존 o1‑mini 대비 더 빠른 응답 시간과 향상된 추론 능력을 제공하면서, 비용 효율성을 극대화하는 것에 중점을 두었습니다.
- 주요 기능:
- 함수 호출(Function Calling), 구조화된 출력(Structured Outputs), 개발자 메시지 지원 등 개발자들이 요구하는 기능들을 처음부터 지원합니다.
- 사용 대상: ChatGPT의 Plus, Team, Pro 사용자뿐만 아니라, 무료 사용자도 메시지 작성기에서 ‘Reason’ 옵션 선택을 통해 체험할 수 있습니다.
o3‑mini‑high: 고급 분석과 심화 추론을 위한 옵션
- 주요 목표: o3‑mini의 강점을 기반으로, 특히 코딩이나 논리 문제와 같이 높은 수준의 추론이 필요한 작업에 최적화되었습니다.
- 특징:
- 고지능 응답: 보다 깊은 단계의 reasoning을 통해 정교한 문제 해결 및 코드 생성에 유리하며, 약간의 추가 처리 시간이 소요됩니다.
- 프로 사용자를 위한 옵션: Pro 등 유료 사용자들이 선택하여 무제한으로 사용할 수 있습니다.
전작 o1(및 o1‑mini)과의 성능 비교
1. 추론 능력 및 정확도




- STEM 분야 최적화:
- o3‑mini는 수학(AIME 2024), 과학(GPQA Diamond) 문제 등에서 전작 o1‑mini에 비해 56% 이상 선호되는 응답을 생성하고, 어려운 문제에서 주요 오류율이 약 39% 감소한 것으로 평가되었습니다.
- o3‑mini‑high는 특히 높은 추론 노력이 필요한 경우, 복잡한 수학 문제와 코딩 문제 해결에서 o1 및 o1‑mini보다 더 우수한 성능을 보입니다.
2. 응답 속도 및 지연 시간
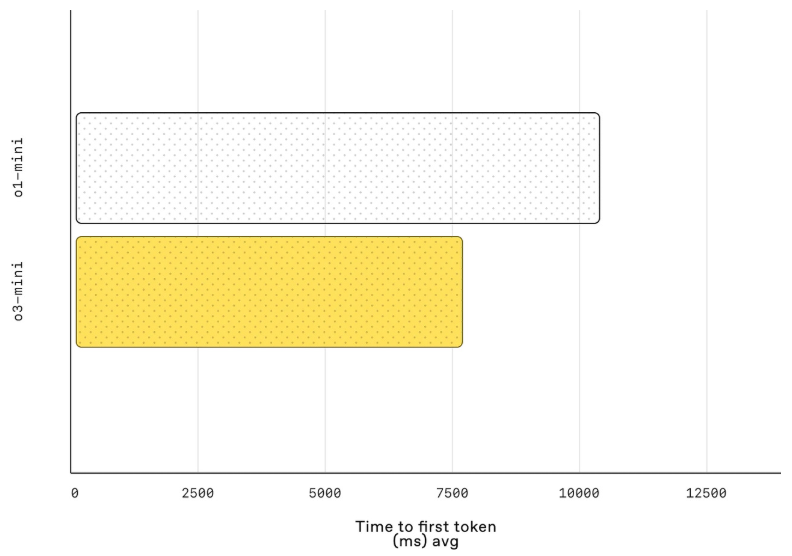
- 빠른 응답:
- A/B 테스트 결과, o3‑mini는 전작 o1‑mini보다 평균 응답 시간이 약 10.16초에서 7.7초로 24% 단축되었으며, 첫 토큰 출력 시간도 평균 2500ms 빠른 것으로 나타났습니다.
- 이러한 속도 개선은 특히 실시간 대화나 코딩, 복잡한 계산 작업에서 사용자 경험을 크게 향상시킵니다.
3. 비용 효율성
- 경제적 활용:
- o3‑mini는 GPT‑4 출시 이후 per-token 가격을 대폭 절감한 제품으로, 높은 성능을 유지하면서도 비용 효율성을 극대화했습니다.
- 다만, o3‑mini‑high의 경우 추가 계산 리소스를 요구하기 때문에 약간의 비용 상승이 있을 수 있으나, 복잡한 문제 해결에 필요한 경우 투자 가치가 충분합니다.
- 기존 ChatGPT Plus 기준, 이전 o1 모델은 주에 50 메세지, o1-mini 모델은 하루 50 메세지 제한이었지만 이번 o3-mini와 o3-mini-high는 하루 150 메세지 제한으로 그 제한이 대폭 늘어났습니다.
4. 안전성 및 탈옥 방지


- 강화된 안전 메커니즘:
- o3‑mini 및 o3‑mini‑high 모두 ‘deliberative alignment’라는 새로운 안전성 훈련 기법을 도입해, AI가 응답 전에 안전 사양을 검토하도록 훈련되었습니다.
- 이로 인해 GPT‑4o와 비교해도 더욱 견고한 안전성과 탈옥 방어 능력을 보여줍니다.
지금까지 o3-mini와 o3-mini-high의 공개된 성능들을 살펴보았습니다.
다만 실제로 사용하여 느끼는 것은 다를 수 있을 것 같은데요.
제가 직접 사용해본 결과로는, 논리적인 질문에 대해 o1과 비교하였을 때
o3-mini의 경우에는 o1에 비해서는 살짝 만족도가 떨어지는 느낌이었지만
o3-mini-high의 경우에는 거의 o1과 유사한 정도의 만족도있는 답변을 얻을 수 있었습니다.
그럼에도 불구하고 기존 o1은 plus 사용자인 저의 입장에선 논리 질문을 이어나가기엔
다소 토큰이 부족하다 느껴졌던 것에 비해
o3-mini-high는 토큰을 적게 먹어 충분히 많은 질문을 이어나갈 수 있었다는 점이 마음에 들었습니다.
지금까지 DeepSeek의 R1 모델 공개 이슈와
그에 따른 ChatGPT의 신작 o3-mini, o3-mini-high의 소개와 성능 비교에 대해 알아보았습니다.
감사합니다!

'시사 정보' 카테고리의 다른 글
| 창업기업 373개사에 사업화 자금 최대 3억 원 지원 (0) | 2025.02.19 |
|---|---|
| 직장인을 위한 AI·디지털 역량 강화! 정부, 169억 원 투입한 온라인 교육 지원 (0) | 2025.02.19 |
| 어디서나 써먹기 좋은 아재 개그 넌센스 퀴즈 1탄! (0) | 2025.01.08 |
| 티스토리 5분만에 구글 애드센스 신청하기! 신청하는 방법! (0) | 2025.01.03 |
| 티스토리 5분만에 네이버 애널리틱스 등록하기! (0) | 2025.01.02 |



